
آنچه در این مقاله میخوانید
امبدینگها مقادیری همچون کلمات، تصاویر یا ویدیوها را به شکلی نمایش میدهند که کامپیوترها بتوانند پردازششان کنند. همچنین امکان جستوجوی شباهت را فراهم کرده و پایهای اساسی در فعالیت هوش مصنوعی به حساب میآیند.
امبدینگ (Embedding) چیست؟
امبدینگها مقادیری مانند متن، تصاویر و صوت را به نمایش میگذارند و بهگونهای طراحی شدهاند که در مدلهای یادگیری ماشین و الگوریتمهای جستوجوی معنایی مورد استفاده قرار بگیرند. امبدینگها چنین مقادیری را براساس مشخصههایشان و دستههایی که بهشان تعلق دارند به شکلی از ریاضی درمیآورند.
آنها در اصل به مدلهای یادگیری ماشین امکان این را میدهند تا مقادیر مشابه را پیدا کنند. مدلهای یادگیری ماشین که از امبدینگها بهره میبرند، وقتی عکس یا سندی را دریافت میکنند میتوانند عکسها یا اسناد مشابهی را نیز بیابند.

بردارها در یادگیری ماشین چه نقشی دارند؟
امبدینگها از لحاظ فنی بردارهایی هستند که از طریق مدلهای یادگیری ماشین ایجاد میشوند تا اطلاعات معناداری درباره مقادیر جمعآوری کنند.
بردارها در ریاضیات آرایههایی از اعدادند که هرکدام نقطهای را در فضایی چندبعدی تعریف میکنند. هر عدد نشان میدهد که مقادیر نامبرده در چه ابعادی قرار دارند.
استفاده از بردارها در یادگیری ماشین امکان جستوجوی مقادیر مشابه را فراهم میکند. الگوریتمهایی که بردارها را جستوجو میکنند میتوانند دو بردار دیگری را پیدا کنند که در پایگاه داده برداری به هم نزدیک هستند.
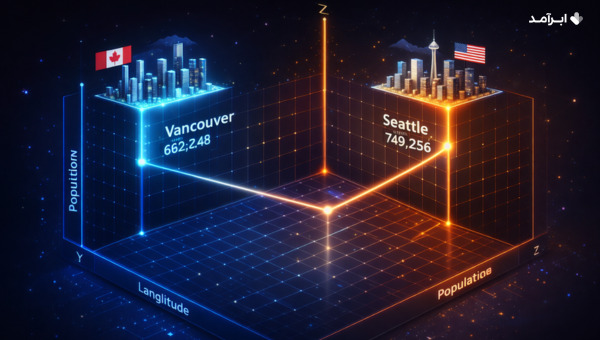
بردارها را همانند طول و عرض جغرافیایی در نظر بگیرید. این دو بعد شمالیجنوبی و شرقیغربی میتوانند موقعیت هر مکانی را روی زمین نشان دهند. مثلاً شهر ونکوور در کانادا با مختصات {۴۹°۱۵’۴۰”ش، ۱۲۳°۰۶’۵۰”غ} نشان داده میشود. این فهرست که از دو مقدار تشکیل شده است، برداری ساده به حساب میآید.
حال تصور کنید بخواهید شهری را پیدا کنید که بسیار نزدیک به ونکوور است. انسانها در این مواقع فقط به موقعیت شهرها روی نقشه نگاه میکنند اما یادگیری ماشین به جای این کار میتواند به طول و عرض جغرافیایی (یا بردار) نگاه کرده و مکانی با طول و عرض جغرافیایی مشابه پیدا کند. شهر بِرنابی در مختصات {۴۹°۱۶’ش، ۱۲۲°۵۸’غ} قرار دارد که بسیار نزدیک به مختصات شهر ونکوور است. بنابراین یادگیری ماشین میتواند به درستی نتیجه بگیرد که شهر برنابی در نزدیکی ونکوور واقع شده است.
افزودن ابعاد بیشتر به بردارها
حال تصور کنید که بخواهید شهری را پیدا کنید که نهتنها نزدیک به ونکوور باشد بلکه اندازه مشابهی نیز داشته باشد. در این حالت بعد سومی نیز علاوه بر طول و عرض جغرافیایی به میان میآید. چنین بعدی اندازه جمعیت نام دارد. میزان جمعیت میتواند به بردار هر شهری اضافه شود و اندازه جمعیت میتواند مانند محور Z در کنار طول و عرض جغرافیایی به ترتیب محورهای X و Y در نظر گرفته شود.
بردار ونکوور باید بدین شکل باشد: {۴۹°۱۵’۴۰”ش، ۱۲۳°۰۶’۵۰”غ، ۶۶۲,۲۴۸}. شهر برنابی پس از بعد سومش دیگر به ونکوور نزدیک نیست چراکه جمعیت برنابی (در سال ۲۰۲۱) تنها ۲۴۹,۱۲۵ [بوده] است. ممکن است یادگیری ماشین بهجای شهر برنابی شهر سیاتل در ایالات متحده را پیدا کند که بردار آن {۴۷°۳۶’۳۵”ش، ۱۲۲°۱۹’۵۹”غ، ۷۴۹,۲۵۶} شبیه به شهر ونکوور است (این آمار متعلق به سال ۲۰۲۲ است).
مثالی که ذکر شد مثالی نسبتاً ساده از نحوه عملکرد بردارها و جستوجوی شباهت محسوب میشود. ممکن است مدلهای یادگیری ماشین در واقعیت بخواهند بیش از سه بعد را تشکیل بدهند که این امر بردارهای بسیار پیچیدهتری میسازد.
بردارهایی با ابعاد بیشتر
چگونه یادگیری ماشین میتواند تشخیص دهد که کدام سریالها شبیه به هم هستند و مخاطب یکسانی خواهند داشت؟ یک سری از مواردی که باید در نظر گرفته شوند به شرح زیر است:
- طول قسمتها
- تعداد قسمتها
- سبک سریال
- تعداد بینندگان
- بازیگران سریال
- سال شروع پخش
تمامی این موارد میتوانند جزوی از ابعاد باشند و هر سریال نیز به مثابه نقطهای در هر یک از این ابعاد نمایش داده میشود.
بردارهای چندبعدی میتوانند به ما کمک کنند که تعیین کنیم آیا سریال کمدی ساینفلد شبیه به سریال ترسناک ونزدی است یا خیر. سریال ساینفلد از سال ۱۹۸۹ و ونزدی از سال ۲۰۲۲ آغاز شده. طول قسمتهای این دو سریال با یکدیگر متفاوت بوده و هر قسمت از سریال ساینفلد ۲۲ الی ۲۴ دقیقه و هر قسمت از سریال ونزدی ۴۶ الی ۵۷ دقیقه است. مقایسه باقی مشخصهها نیز به همین شکل است. وقتی به بردارهای این دو سریال را نگاه میکنیم میتوانیم ببینیم که این سریالها احتمالاً جایگاه بسیار متفاوتی در ابعاد سریالها خواهند داشت.
میتوانیم اطلاعات بهدستآمده را همانند طول و عرض جغرافیایی اما با مقادیری بیشتر بهصورت بردار بیان کنیم:
- بردار سریال ساینفلد: {[کمدی موقعیت]، ۱۹۸۹، ۲۲-۲۴، ۹، ۱۸۰}
- بردار سریال ونزدی: {[ترسناک]، ۲۰۲۲، ۴۶-۵۷، ۱، ۸}
مدل یادگیری ماشین ممکن است سریال کمدی چیْرز را بسیار شبیهتر به سریال ساینفلد شناسایی کند. این سریال از ژانر یکسانی است، در سال ۱۹۸۲ آغاز شده، طول قسمتهای آن ۲۱ الی ۲۵ دقیقه است، ۱۱ فصل دارد و شامل ۲۷۵ قسمت است.
- بردار سریال ساینفلد: {[کمدی موقعیت]، ۱۹۸۹، ۲۲-۲۴، ۹، ۱۸۰}
- بردار سریال چیرز: {[کمدی موقعیت]، ۱۹۸۲، ۲۱-۲۵، ۱۱، ۲۷۵}
در مثال نخست، شهرها نقطهای در امتداد دو بعد طول و عرض جغرافیایی قرار میگرفتند و سپس بعد سوم یعنی جمعیت را بهشان اضافه میکردیم.
سریالها در حافظه یادگیری ماشین بهجای دو، سه یا پنج بعد، نقطهای در امتداد صدها یا هزاران بعد هستند که تعدادشان وابسته به یادگیری ماشین خواهد بود.

امبدینگها چگونه کار میکنند؟
امبدینگ به فرآیندی گفته میشود که بردارها را با استفاده از یادگیری عمیق تشکیل میدهد. در واقع امبدینگها خروجی چنین فرآیندی به حساب میآیند. به عبارت دیگر بردارهایی که از طریق یادگیری عمیق تشکیل میشوند بهمنظور جستوجوی شباهت مورد استفاده قرار میگیرند.
امبدینگهایی را که به هم نزدیک هستند میتوان مشابه در نظر گرفت، همانطور که شهرهای سیاتل و ونکوور از لحاظ طول و عرض جغرافیایی نزدیک به هم هستند و میتوان جمعیتشان را مقایسه کرد. الگوریتمها با استفاده از امبدینگ میتوانند پیشنهادهای مرتبط را به مخاطب ارائه دهند، مکانهای مشابه را پیدا کنند یا تشخیص دهد که کدام کلمات احتمالاً در کنار هم میآیند یا مشابه یکدیگر هستند. این امر به همینشکل در مدلهای زبانی انجام میگیرد.
شبکههای عصبی چگونه امبدینگها را تشکیل میدهند؟
شبکههای عصبی همان مدلهای یادگیری عمیقی هستند که ساختار مغز انسان را تقلید میکنند. همانطور که مغز از نورونهایی تشکیل شده که تکانههای الکتریکی را به یکدیگر ارسال میکنند، شبکههای عصبی نیز از گرههای مجازی تشکیل شدهاند که وقتی ورودیهایشان از آستانهای مشخص فراتر میرودند با یکدیگر ارتباط برقرار میکنند.
شبکههای عصبی از چندین لایه ساخته شدهاند:
- لایه ورودی
- لایه خروجی
- لایههای پنهان
لایههای پنهان میتوانند بسته به اینکه مدل چگونه تعریف شده است ورودیها را به شیوههای مختلفی تغییر دهند.
امبدینگها در لایه پنهان ساخته میشوند. این فرآیند معمولاً قبل از پردازش ورودی در لایههای اضافی اتفاق میافتد. بنابراین مثلاً انسانها نیازی ندارند که مشخص کنند هر سریال در صد بعد مختلف چه جایگاهی خواهد داشت اما لایههای پنهان در شبکه عصبی این کار را بهطور خودکار انجام میدهند. سپس لایههای پنهان دیگر میتوانند سریالی را با استفاده از چنین امبدینگهایی بیشتر تحلیل کنند تا سریالهای مشابه را بیابند. در نهایت، لایه خروجی میتواند سریالهای دیگری را که بینندگان ممکن است بخواهند تماشا کنند پیشنهاد دهد.

ساختن چنین لایههای امبدینگ در ابتدا باید بهصورت دستی انجام گیرد. در آغاز لازم است برنامهنویسان به شبکههای عصبی مثالهایی را از چگونگی تشکیلدهی امبدینگ، ابعادی که باید شامل شوند و غیره بدهند. در نهایت، لایه امبدینگ میتواند بهطور خودکار عمل کند. البته ممکن است برنامهنویسان همچنان به کارشان ادامه دهند تا مدل را دقیقتر تنظیم کنند که پیشنهادهای بهتری به مخاطب بدهد.
امبدینگها در مدلهای زبانی بزرگ چگونه استفاده میشوند؟
فرآیند تشکیل امبدینگ در مدلهای زبانی بزرگ نظیر مدلهای مورد استفاده در ابزارهای هوش مصنوعی مانند چتجیپیتی از این هم پیشرفتهتر است. چنین فرآیندی در مدلهای زبانی بزرگ علاوه بر خود کلمه بافت هر کلمه را نیز امبدینگ میکند. معنای کل جملات، پاراگرافها و متن را میتوان در این حالت جستوجو و تحلیل کرد. گرچه این امر به قدرت محاسباتی چشمگیری نیاز دارد اما بافت پرسشها با همان فرآیندها امبدینگ نمیشود. در نتیجه، امبدینگها زمان و قدرت محاسباتی را صرف پرسشهای آتی میکند. منبع
ارتباط با ما
- امبدینگ چه فرقی با عددیسازی معمولی دادهها دارد؟
امبدینگ فقط «تبدیل به عدد» نیست، بلکه «تبدیل معنا به موقعیت» است. طوری عددی میکند که دادههای هممعنا به هم نزدیک بمانند، نه اینکه فقط قابلشمارش شوند.
- مفاهیم کیفی مثل ژانر یا احساس چطور وارد امبدینگ میشوند؟
شبکه عصبی با دیدن مثالهای زیاد یاد میگیرد این مفاهیم معمولاً کنار چه ویژگیهایی میآیند. نتیجه این میشود که مفاهیم کیفی، بدون تعریف مستقیم، به بردارهای عددی تبدیل میشوند.
- آیا امبدینگها واقعاً «میفهمند»؟
نه به معنای انسانی. آنها معنا را حس نمیکنند، اما ساختار شباهتهای معنایی را آنقدر دقیق مدل میکنند که رفتاری شبیه فهم از خود نشان میدهند.
این مقاله را به اشتراک بگذارید
به این مطلب امتیاز دهید
مطالب مرتبط:

")
